Dans un monde où les données se multiplient de façon exponentielle, les organisations font face à un défi majeur : comment tirer parti d’informations dispersées dans des dizaines de systèmes ? La réponse se trouve souvent dans la mise en place d’un integrated data repository, une architecture qui centralise vos données en un actif cohérent et gouverné. Cette approche transforme radicalement votre capacité à analyser, décider et agir. Vous réduisez les erreurs dues aux incohérences, accélérez la production de rapports et instaurez une culture data-driven au sein de vos équipes. Ce guide vous dévoile les principes fondamentaux, les bénéfices concrets et les bonnes pratiques pour réussir votre projet.
Comprendre l’integrated data repository dans un paysage de données fragmenté
La prolifération des applications métier, des bases de données historiques, des fichiers locaux et des solutions cloud crée un paysage de données fragmenté. Chaque système détient une part de vérité, mais aucun ne donne la vision complète. L’integrated data repository propose une réponse structurante en rassemblant ces sources dans une architecture unifiée, sans forcément remplacer vos systèmes existants. Il agit comme un orchestrateur qui harmonise, nettoie et rend cohérentes vos données pour tous les usages.
Les fondamentaux d’un integrated data repository et sa place dans l’écosystème
Un integrated data repository est un environnement centralisé qui agrège des données issues de multiples systèmes sources. Son rôle consiste à créer une source de vérité unique et fiable, exploitable par les équipes analytiques, opérationnelles et les responsables de la conformité. Concrètement, il collecte les données depuis vos ERP, CRM, systèmes de production et autres applications, puis applique des transformations pour les normaliser et les enrichir.
Ce référentiel ne vit pas en autarcie. Il s’inscrit dans un écosystème aux côtés du data warehouse pour les analyses structurées, du data lake pour le stockage massif de données brutes, et des systèmes opérationnels qui génèrent les données en temps réel. Sa fonction est d’assurer la cohérence entre tous ces composants et de fournir aux utilisateurs un accès simplifié à des informations de qualité.
En quoi un integrated data repository se distingue de data warehouse et data lake
Le data warehouse excelle dans le stockage de données structurées, optimisées pour le reporting et les tableaux de bord. Il répond à des questions prédéfinies avec rapidité et efficacité. Le data lake, quant à lui, accueille de très gros volumes de données dans leur format brut, qu’elles soient structurées, semi-structurées ou non structurées. Il offre une grande flexibilité pour l’exploration et l’analytique avancée.
L’integrated data repository se positionne comme une couche intermédiaire et orchestrante. Il ne remplace ni le warehouse ni le lake, mais les connecte et les harmonise. Il applique des règles de gouvernance, de qualité et d’intégration pour transformer les données brutes en informations exploitables. En pratique, il peut puiser dans un data lake, appliquer des transformations et alimenter un data warehouse, tout en servant directement certains usages métier.
| Solution | Objectif principal | Type de données |
|---|---|---|
| Data warehouse | Reporting et BI structurés | Données structurées, modélisées |
| Data lake | Stockage massif et exploration | Données brutes, tous formats |
| Integrated data repository | Intégration, qualité, gouvernance | Données harmonisées, multi-sources |
Quels sont les principaux cas d’usage métier d’un integrated data repository
Les organisations utilisent l’integrated data repository pour répondre à des besoins très variés. Dans le secteur bancaire, il consolide les données clients dispersées entre systèmes de crédit, comptes courants, placements et assurances pour offrir une vue 360° et respecter les exigences réglementaires. Dans la santé, il rassemble dossiers médicaux, résultats d’analyses et données administratives pour améliorer le parcours patient et la recherche clinique.
Le reporting réglementaire constitue un cas d’usage fréquent. Les entreprises doivent produire des déclarations précises aux autorités de contrôle, ce qui nécessite de tracer les données, leurs transformations et de garantir leur cohérence. L’integrated data repository facilite cette traçabilité et simplifie les audits.
Autre exemple courant : le self-service analytics. Les équipes métier peuvent accéder à des jeux de données fiables, documentés et gouvernés sans solliciter systématiquement l’IT. Cela accélère les analyses et encourage l’autonomie dans la prise de décision.
Bénéfices clés d’un integrated data repository pour la gouvernance et l’analytics

Au-delà de la centralisation technique, l’integrated data repository délivre des avantages concrets qui impactent directement la performance et la maîtrise des risques. Vous gagnez en fiabilité, réduisez les silos organisationnels et facilitez la conformité réglementaire. Ces bénéfices se traduisent par une meilleure qualité de décision et une efficacité opérationnelle accrue.
Comment un integrated data repository améliore fiabilité et cohérence des données
Lorsque chaque département utilise ses propres extractions de données, les divergences apparaissent rapidement. Le chiffre d’affaires annoncé par les ventes ne correspond pas à celui du contrôle de gestion, et les débats interminables commencent. Un integrated data repository applique des règles communes de transformation, de validation et de normalisation à toutes les données.
Prenons l’exemple d’un groupe industriel. Avant la mise en place du référentiel intégré, chaque filiale calculait ses indicateurs de production selon des méthodes locales. Résultat : les reportings groupe manquaient de cohérence et nécessitaient d’importants retraitements manuels. Après centralisation dans un integrated data repository, les mêmes règles s’appliquent partout, les KPI deviennent comparables et la confiance dans les chiffres se renforce.
Réduire les silos et fluidifier la collaboration entre équipes métier et IT
Les silos de données alimentent des silos organisationnels. Quand chaque service possède sa vérité, la collaboration devient compliquée. L’integrated data repository crée un langage commun entre métiers, data engineers, data analysts et équipes IT. Tous accèdent au même socle de données, documenté et gouverné.
Concrètement, un responsable marketing peut consulter les mêmes données client que l’équipe service après-vente ou la direction financière. Les échanges se simplifient car tout le monde parle des mêmes chiffres. Les projets analytiques avancent plus vite, avec moins d’allers-retours pour clarifier les définitions ou réconcilier des écarts inexpliqués.
En quoi un integrated data repository facilite reporting réglementaire et conformité
Pour respecter les réglementations comme RGPD, Solvabilité II, Bâle III ou IFRS, vous devez documenter précisément l’origine de vos données, les transformations appliquées et les contrôles effectués. L’integrated data repository trace toutes ces opérations et permet de justifier chaque chiffre présenté aux autorités.
Lors d’un audit, vous pouvez rejouer les calculs, expliquer les sources et démontrer que les règles métier ont bien été appliquées. Cette capacité à prouver la cohérence et la traçabilité réduit fortement les risques de sanctions réglementaires. Dans le secteur pharmaceutique, par exemple, la traçabilité des données d’essais cliniques devient un impératif absolu que l’integrated data repository sécurise efficacement.
Architecture et composants essentiels d’un integrated data repository moderne
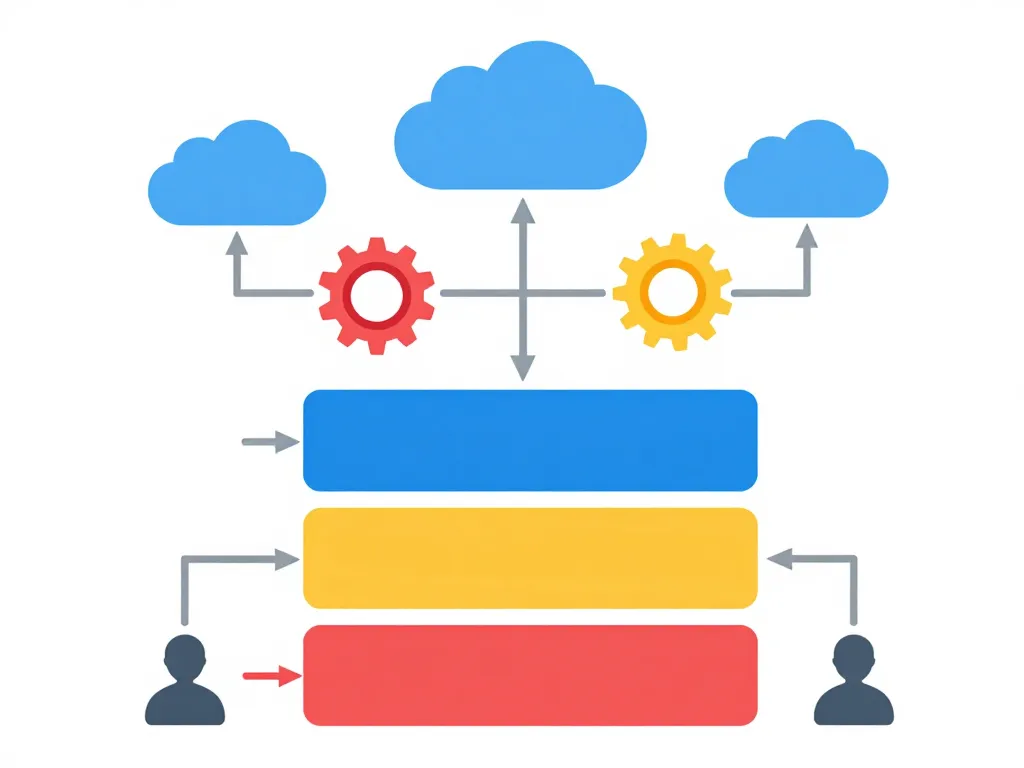
Construire un integrated data repository ne se résume pas à installer une base de données centrale. Il faut penser une architecture complète, qui couvre l’ingestion, l’intégration, le stockage, la gouvernance et l’exposition des données. Cette approche globale garantit que le référentiel réponde aux besoins actuels tout en restant évolutif.
Les couches techniques essentielles : ingestion, intégration, stockage et exposition
La couche d’ingestion collecte les données depuis les systèmes sources. Elle peut s’appuyer sur des processus ETL traditionnels pour extraire, transformer et charger les données, ou sur des architectures ELT qui chargent d’abord les données brutes puis les transforment. Pour les besoins temps réel, le streaming de données via Kafka ou des technologies similaires devient indispensable.
La couche d’intégration applique les règles métier. Elle nettoie les données, résout les doublons, enrichit les informations avec des référentiels externes et applique les mappings entre différents formats. C’est ici que se joue la qualité finale des données.
Le stockage organise les données harmonisées en domaines métier ou en couches logiques. Certaines organisations privilégient des modèles dimensionnels pour les performances analytiques, d’autres adoptent des approches plus flexibles comme le data vault pour gérer la complexité.
La couche d’exposition met les données à disposition via des API, des vues SQL, des outils de BI ou des notebooks pour les data scientists. Elle adapte la présentation des données aux différents usages et profils d’utilisateurs.
Intégrer data warehouse, data lake et systèmes opérationnels dans un seul référentiel
Les architectures modernes ne partent pas d’une page blanche. Vous disposez déjà d’un data warehouse pour vos rapports financiers, d’un data lake pour vos projets d’IA et de systèmes opérationnels critiques. L’integrated data repository doit composer avec cet existant.
Les approches de type data lakehouse combinent la flexibilité du data lake avec la structure du data warehouse. Le concept de data fabric va plus loin en orchestrant les échanges entre tous les environnements sans imposer de migration massive. Vous conservez vos investissements tout en gagnant une vision intégrée.
Prenons une entreprise de distribution. Son data warehouse gère les ventes et la finance, son data lake stocke les logs web et les données IoT de ses entrepôts. L’integrated data repository fédère ces sources pour créer des analyses prédictives de la demande qui combinent historique de ventes, comportement web et stocks en temps réel.
Quels rôles jouent metadata, data catalog et data governance dans ce dispositif
Les métadonnées décrivent vos données : leur origine, leur signification métier, leur fraîcheur, leur qualité. Sans métadonnées riches, les utilisateurs perdent du temps à chercher les bonnes sources ou utilisent des données inappropriées.
Le data catalog rend ces métadonnées accessibles. Il fonctionne comme un moteur de recherche interne où analyste métier, data scientist ou auditeur peut trouver rapidement le jeu de données dont il a besoin, comprendre sa structure et vérifier sa fiabilité.
La data governance formalise les règles du jeu. Elle définit qui peut accéder à quelles données, qui est responsable de leur qualité, comment gérer les demandes d’évolution et comment garantir la sécurité. Un comité de gouvernance réunit représentants métier et IT pour arbitrer ces questions. Sans gouvernance, même le meilleur référentiel technique finit par devenir ingérable.
Mettre en place un integrated data repository aligné avec vos enjeux métier
La technologie ne fait pas tout. La réussite d’un projet d’integrated data repository repose sur une démarche stratégique, une gouvernance pragmatique et un accompagnement des utilisateurs. Partir des bonnes priorités, éviter les pièges classiques et mesurer les résultats font la différence entre succès et échec.
Par où commencer pour structurer un projet d’integrated data repository
Commencez par identifier les usages prioritaires. Quel problème métier voulez-vous résoudre en premier ? Améliorer le reporting financier, mieux connaître vos clients, accélérer le time-to-market de vos analyses ? Concentrez-vous sur un ou deux cas d’usage critiques plutôt que de vouloir tout traiter d’emblée.
Définissez ensuite le périmètre initial. Quels domaines de données sont nécessaires pour ces usages ? Quelles sources devez-vous connecter ? Un pilote bien cadré sur un périmètre limité permet de démontrer rapidement la valeur et d’apprendre avant d’étendre l’initiative.
Établissez une feuille de route par étapes. Après le pilote, quels autres domaines intégrer ? Comment industrialiser les processus de qualité et d’intégration ? Cette vision progressive rassure les parties prenantes et permet d’ajuster le tir en cours de route.
Comment choisir technologies et architecture pour votre integrated data repository
Le choix technologique dépend de plusieurs facteurs. Vos contraintes réglementaires vous imposent-elles de garder certaines données sur site ? Avez-vous les compétences internes pour gérer des solutions open source ou préférez-vous des plateformes managées dans le cloud ?
Les solutions cloud comme Azure Synapse, Google BigQuery ou AWS Redshift offrent scalabilité et rapidité de déploiement. Les approches hybrides combinent on-premise et cloud pour répondre à des contraintes de souveraineté ou de latence. Les outils open source comme Apache Spark, Trino ou dbt donnent flexibilité et maîtrise mais nécessitent davantage d’expertise.
L’essentiel est de garantir interopérabilité et évolutivité. Votre architecture doit supporter la croissance des volumes, l’ajout de nouvelles sources et l’évolution des usages sans refonte majeure.
Quelles erreurs fréquentes éviter lors de la mise en œuvre d’un référentiel intégré
La première erreur consiste à viser un périmètre trop large dès le départ. Vouloir intégrer toutes les données de l’entreprise en une seule fois conduit à des projets de plusieurs années qui n’accouchent jamais. Privilégiez l’approche itérative.
Deuxième piège : se concentrer uniquement sur la technologie en négligeant la gouvernance et la qualité. Sans règles claires et sans processus de contrôle qualité, votre référentiel se remplit de données douteuses que personne n’utilisera.
Troisième erreur : ignorer les utilisateurs finaux. Un integrated data repository ne sert que s’il répond à des besoins réels et que les équipes savent l’exploiter. L’accompagnement, la formation et la communication sont aussi importants que l’infrastructure technique.
Enfin, sous-estimer les coûts et performances à long terme. Une architecture mal dimensionnée peut rapidement exploser en termes de facturation cloud ou de temps de réponse. Anticipez les volumes futurs et prévoyez des mécanismes d’optimisation.
Comment mesurer la valeur créée par votre integrated data repository au fil du temps
La valeur d’un integrated data repository se mesure d’abord par des gains opérationnels. Combien de temps économisez-vous sur la production des rapports mensuels ? De combien avez-vous réduit les écarts entre les chiffres des différents services ? Ces indicateurs concrets parlent aux directions métier.
Le niveau d’adoption constitue un autre baromètre. Combien d’utilisateurs actifs accèdent régulièrement au référentiel ? Combien de jeux de données sont réutilisés dans plusieurs projets ? Une adoption croissante signale que vous répondez à de vrais besoins.
Mesurez également l’impact sur la qualité de décision. Les projets analytiques aboutissent-ils plus vite ? Les décisions stratégiques s’appuient-elles davantage sur les données ? Ces effets qualitatifs, même difficiles à quantifier, justifient les investissements.
Documentez quelques success stories : un reporting réglementaire qui passait de dix jours à deux jours, une campagne marketing personnalisée rendue possible par la vision 360° client, une détection de fraude améliorée grâce au croisement de sources autrefois isolées. Ces exemples tangibles alimentent l’adhésion interne et ouvrent la voie à de nouveaux usages.
L’integrated data repository transforme vos données dispersées en un actif stratégique cohérent et gouverné. Il améliore la fiabilité de vos analyses, fluidifie la collaboration entre équipes et sécurise vos obligations réglementaires. Sa mise en place demande une approche progressive, centrée sur les usages métier et soutenue par une gouvernance solide. Quand vous réussissez cette transformation, vous ne gérez plus seulement des données : vous construisez un véritable avantage concurrentiel fondé sur l’information.

